Trending papers today
Top 5 trending papers today from my twitter feed

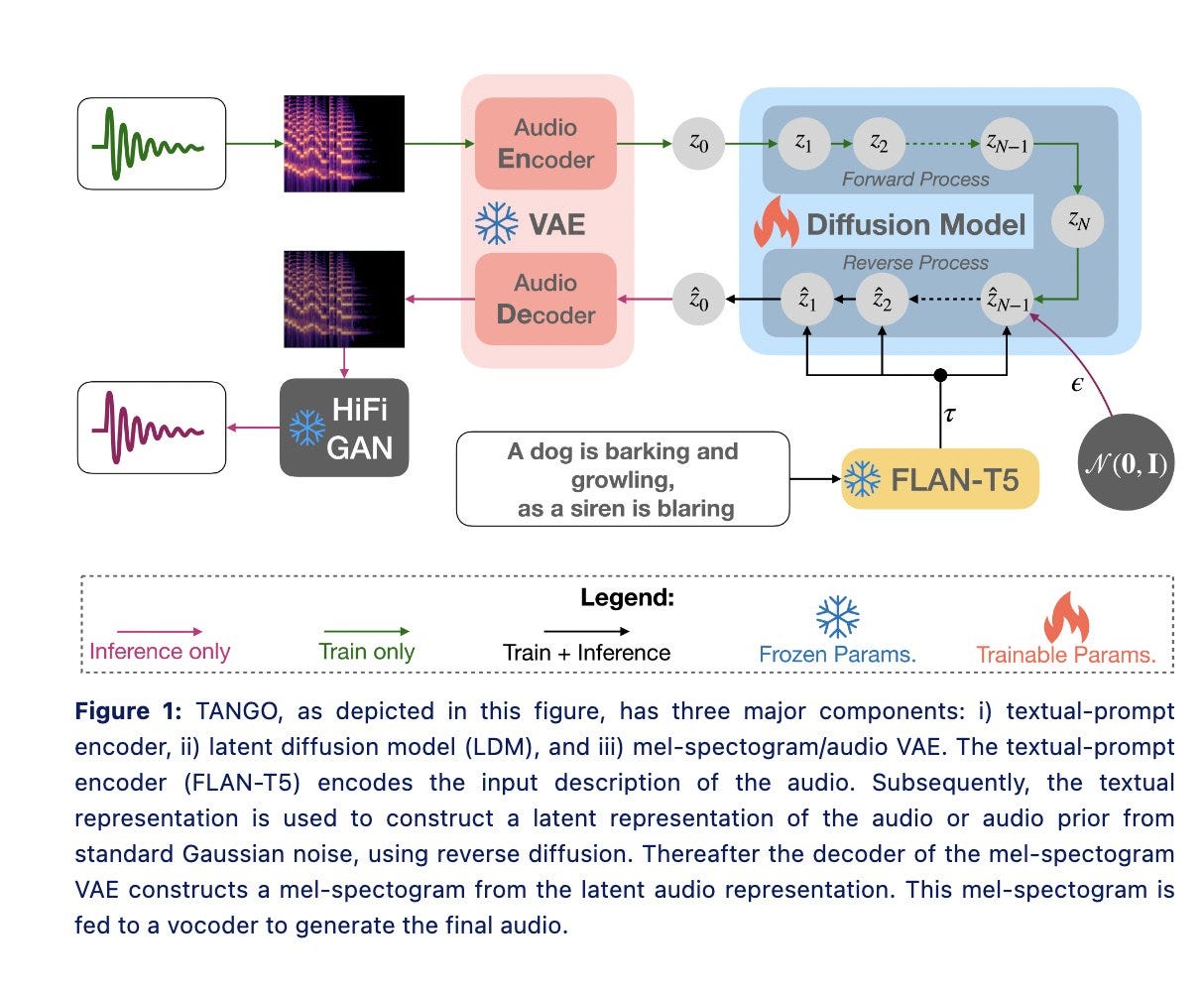
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System
abs: https://arxiv.org/abs/2304.14407
project page: https://wangjunke.info/ChatVideo/

We’re Afraid Language Models Aren’t Modeling Ambiguity

JaxPruner: A concise library for sparsity research

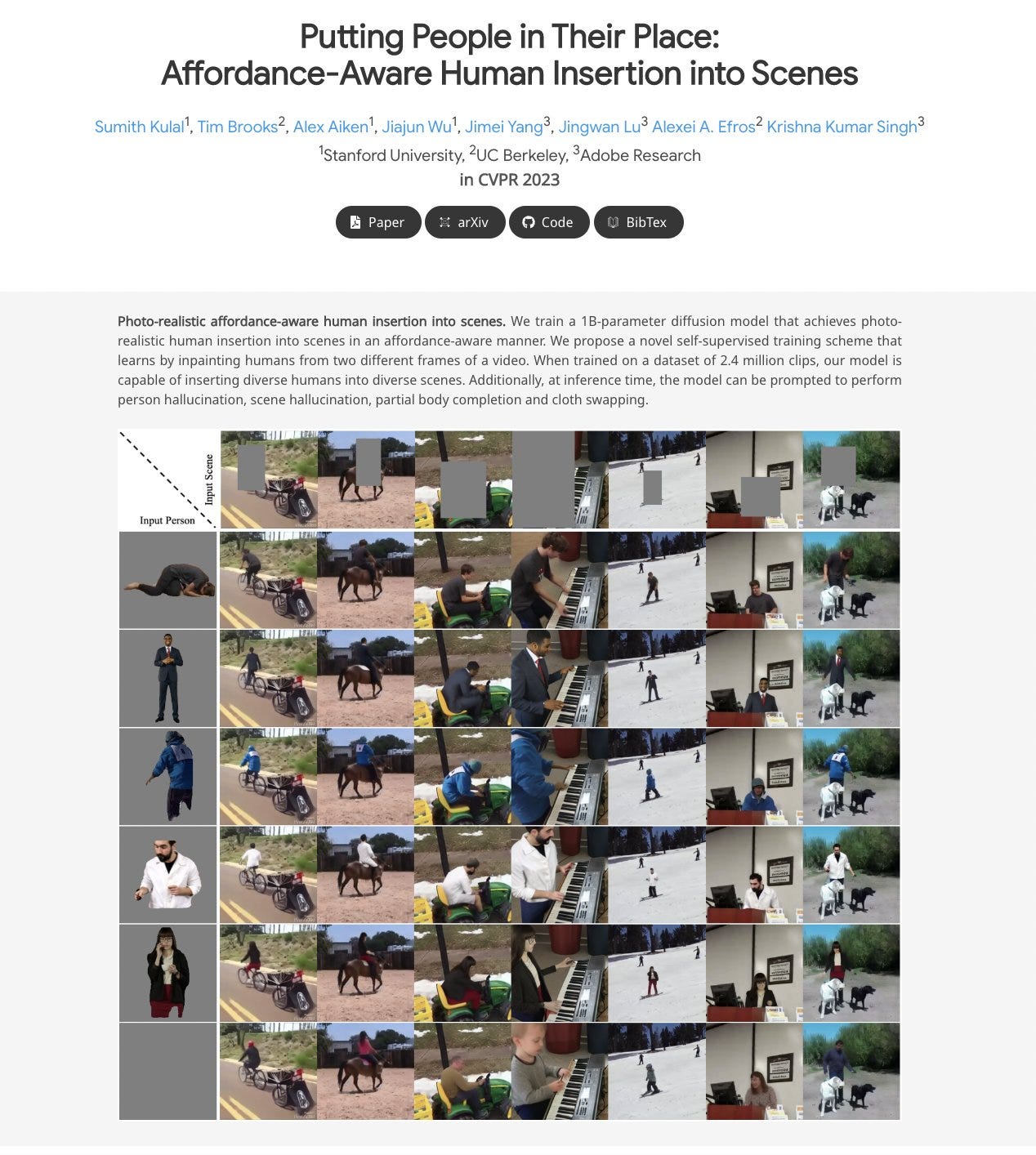
Putting People in Their Place: Affordance-Aware Human Insertion into Scenes abs: https://arxiv.org/abs/2304.14406
project page: https://sumith1896.github.io/affordance-insertion/