


Trending AI papers today
Top 5 trending papers today

Top 5 AI papers
Learning Physically Simulated Tennis Skills from Broadcast Videos
demonstrate that system produces controllers for physically-simulated tennis players that can hit the incoming ball to target positions accurately using a diverse array of strokes (serves, forehands, and backhands), spins (topspins and slices), and playing styles (one/two-handed backhands, left/right-handed play). Overall, system can synthesize two physically simulated characters playing extended tennis rallies with simulated racket and ball dynamics
paper: https://research.nvidia.com/labs/toronto-ai/vid2player3d/data/tennis_skills_main.pdf
project page: https://research.nvidia.com/labs/toronto-ai/vid2player3d/

Is Your Code Generated by ChatGPT Really Correct?
Rigorous Evaluation of Large Language Models for Code Generation extensive evaluation across 14 popular LLMs (including GPT-4 and ChatGPT) demonstrates that HUMANEVAL+ is able to catch significant amounts of previously undetected wrong code synthesized by LLMs, reducing the pass@k by 15.1% on average! For example, the pass@k of widely studied open-source models like CODEGEN-16B can drop by over 18.0%, while the performance of state-of-the-art commercial models like ChatGPT and GPT-4 can also drop by at least 13.0%, largely affect the result analysis for almost all recent work on LLM-based code generation

Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
abs: https://arxiv.org/abs/2305.01569
github: https://github.com/yuvalkirstain/pickscore
build Pick-a-Pic, a large, open dataset of text-to-image prompts and real users' preferences over generated images. Leverage this dataset to train a CLIP-based scoring function, PickScore, which exhibits superhuman performance on the task of predicting human preferences. Then, test PickScore's ability to perform model evaluation and observe that it correlates better with human rankings than other automatic evaluation metrics. Therefore, recommend using PickScore for evaluating future text-to-image generation models, and using Pick-a-Pic prompts as a more relevant dataset than MS-COCO. Finally, demonstrate how PickScore can enhance existing text-to-image models via ranking.


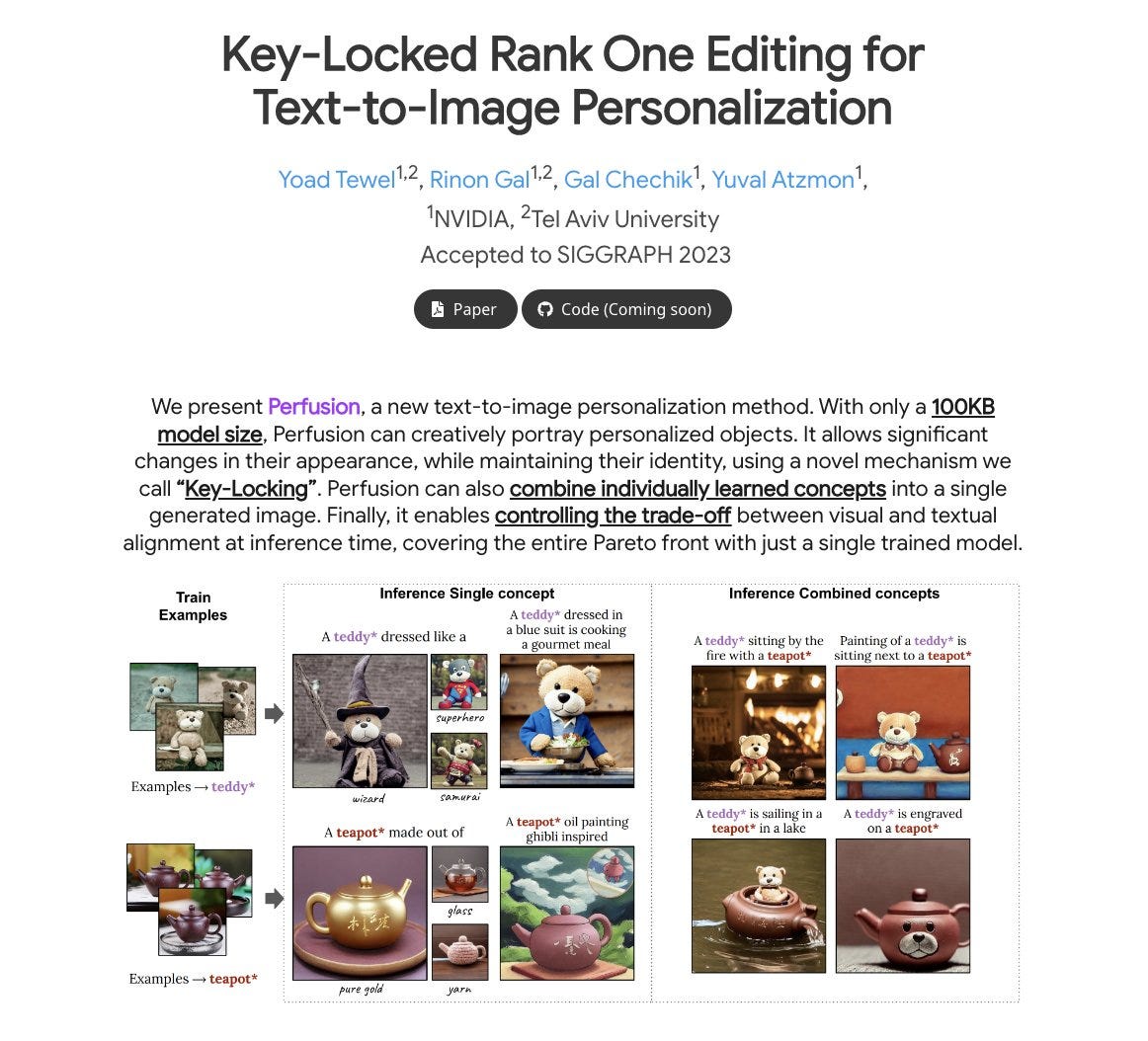
Key-Locked Rank One Editing for Text-to-Image Personalization
present Perfusion, a new text-to-image personalization method. With only a 100KB model size, Perfusion can creatively portray personalized objects. It allows significant changes in their appearance, while maintaining their identity, using a novel mechanism we call “Key-Locking”. Perfusion can also combine individually learned concepts into a single generated image. Finally, it enables controlling the trade-off between visual and textual alignment at inference time, covering the entire Pareto front with just a single trained model
abs: https://arxiv.org/abs/2305.01644
project page: https://research.nvidia.com/labs/par/Perfusion/
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
introduce DreamPaint, a framework to intelligently inpaint any e-commerce product on any user-provided context image
