


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
Amazon is focusing on using A.I. to get stuff delivered to you faster
C3.ai stock pops, company raises outlook amid 'accelerating' AI interest
Top AI papers
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers abs: https://arxiv.org/abs/2305.07185
paper page: https://huggingface.co/papers/2305.07185
abstract: Autoregressive transformers are spectacular models for short sequences but scale poorly to long sequences such as high-resolution images, podcasts, code, or books. We proposed Megabyte, a multi-scale decoder architecture that enables end-to-end differentiable modeling of sequences of over one million bytes. Megabyte segments sequences into patches and uses a local submodel within patches and a global model between patches. This enables sub-quadratic self-attention, much larger feedforward layers for the same compute, and improved parallelism during decoding -- unlocking better performance at reduced cost for both training and generation. Extensive experiments show that Megabyte allows byte-level models to perform competitively with subword models on long context language modeling, achieve state-of-the-art density estimation on ImageNet, and model audio from raw files. Together, these results establish the viability of tokenization-free autoregressive sequence modeling at scale.

ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4
abs: https://arxiv.org/abs/2305.07490
paper page: https://huggingface.co/papers/2305.07490
model: https://huggingface.co/Tyrannosaurus/ArtGPT-4
abstract: In recent years, large language models (LLMs) have made significant progress in natural language processing (NLP), with models like ChatGPT and GPT-4 achieving impressive capabilities in various linguistic tasks. However, training models on such a large scale is challenging, and finding datasets that match the model's scale is often difficult. Fine-tuning and training models with fewer parameters using novel methods have emerged as promising approaches to overcome these challenges. One such model is MiniGPT-4, which achieves comparable vision-language understanding to GPT-4 by leveraging novel pre-training models and innovative training strategies. However, the model still faces some challenges in image understanding, particularly in artistic pictures. A novel multimodal model called ArtGPT-4 has been proposed to address these limitations. ArtGPT-4 was trained on image-text pairs using a Tesla A100 device in just 2 hours, using only about 200 GB of data. The model can depict images with an artistic flair and generate visual code, including aesthetically pleasing HTML/CSS web pages. Furthermore, the article proposes novel benchmarks for evaluating the performance of vision-language models. In the subsequent evaluation methods, ArtGPT-4 scored more than 1 point higher than the current state-of-the-art model and was only 0.25 points lower than artists on a 6-point scale.

Optimizing Memory Mapping Using Deep Reinforcement Learning
abs: https://arxiv.org/abs/2305.07440
paper page: https://huggingface.co/papers/2305.07440
abstract: Resource scheduling and allocation is a critical component of many high impact systems ranging from congestion control to cloud computing. Finding more optimal solutions to these problems often has significant impact on resource and time savings, reducing device wear-and-tear, and even potentially improving carbon emissions. In this paper, we focus on a specific instance of a scheduling problem, namely the memory mapping problem that occurs during compilation of machine learning programs: That is, mapping tensors to different memory layers to optimize execution time. We introduce an approach for solving the memory mapping problem using Reinforcement Learning. RL is a solution paradigm well-suited for sequential decision making problems that are amenable to planning, and combinatorial search spaces with high-dimensional data inputs. We formulate the problem as a single-player game, which we call the mallocGame, such that high-reward trajectories of the game correspond to efficient memory mappings on the target hardware. We also introduce a Reinforcement Learning agent, mallocMuZero, and show that it is capable of playing this game to discover new and improved memory mapping solutions that lead to faster execution times on real ML workloads on ML accelerators. We compare the performance of mallocMuZero to the default solver used by the Accelerated Linear Algebra (XLA) compiler on a benchmark of realistic ML workloads. In addition, we show that mallocMuZero is capable of improving the execution time of the recently published AlphaTensor matrix multiplication model.

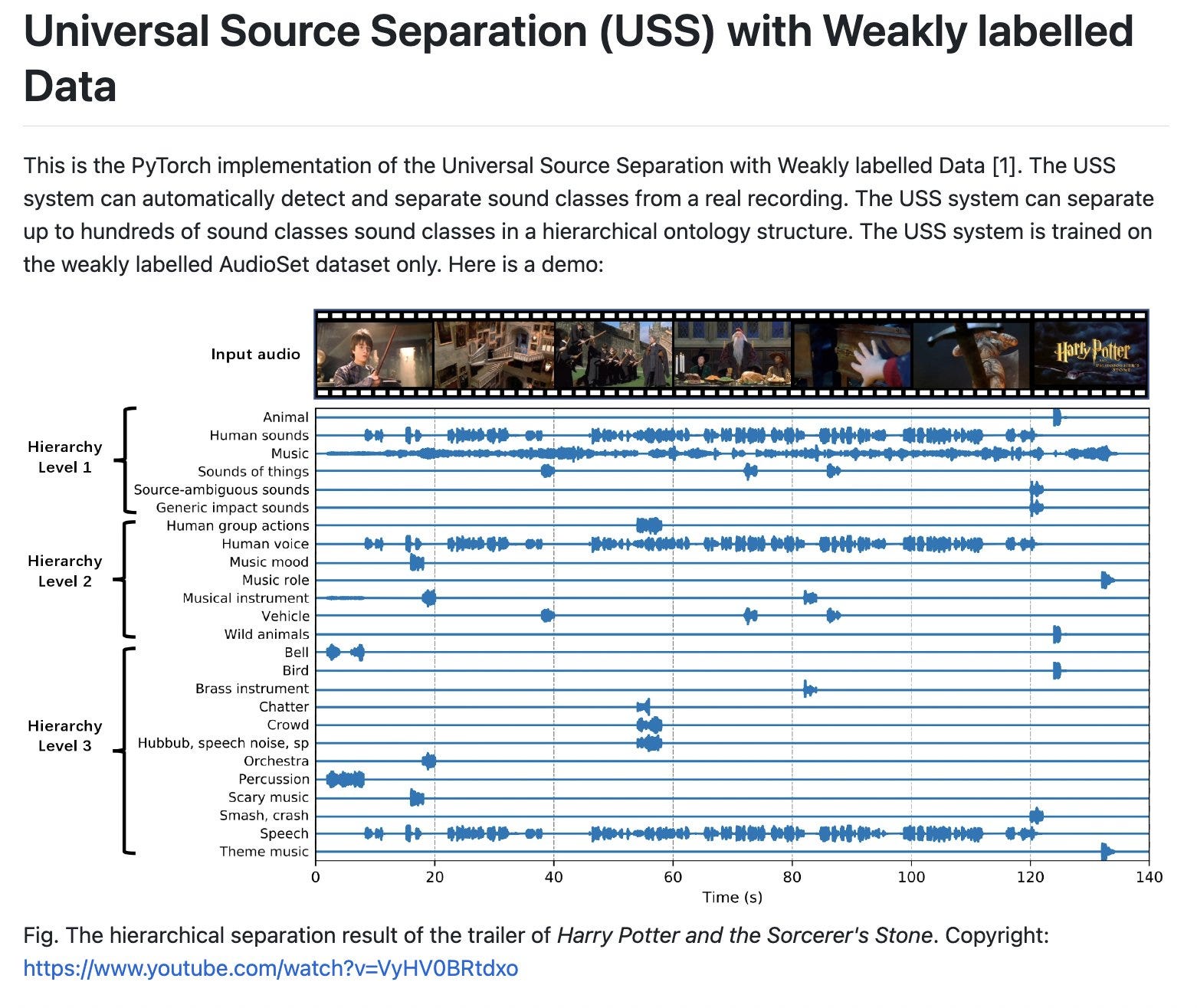
Universal Source Separation with Weakly Labelled Data
abs: https://arxiv.org/abs/2305.07447
paper page: https://huggingface.co/papers/2305.07447
github: https://github.com/bytedance/uss
abstract: Universal source separation (USS) is a fundamental research task for computational auditory scene analysis, which aims to separate mono recordings into individual source tracks. There are three potential challenges awaiting the solution to the audio source separation task. First, previous audio source separation systems mainly focus on separating one or a limited number of specific sources. There is a lack of research on building a unified system that can separate arbitrary sources via a single model. Second, most previous systems require clean source data to train a separator, while clean source data are scarce. Third, there is a lack of USS system that can automatically detect and separate active sound classes in a hierarchical level. To use large-scale weakly labeled/unlabeled audio data for audio source separation, we propose a universal audio source separation framework containing: 1) an audio tagging model trained on weakly labeled data as a query net; and 2) a conditional source separation model that takes query net outputs as conditions to separate arbitrary sound sources. We investigate various query nets, source separation models, and training strategies and propose a hierarchical USS strategy to automatically detect and separate sound classes from the AudioSet ontology. By solely leveraging the weakly labelled AudioSet, our USS system is successful in separating a wide variety of sound classes, including sound event separation, music source separation, and speech enhancement. The USS system achieves an average signal-to-distortion ratio improvement (SDRi) of 5.57 dB over 527 sound classes of AudioSet; 10.57 dB on the DCASE 2018 Task 2 dataset; 8.12 dB on the MUSDB18 dataset; an SDRi of 7.28 dB on the Slakh2100 dataset; and an SSNR of 9.00 dB on the voicebank-demand dataset.
Better speech synthesis through scaling
abs: https://arxiv.org/abs/2305.07243
paper page: https://huggingface.co/papers/2305.07243
abstract: In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise -- an expressive, multi-voice text-to-speech system.
