


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
AI will create ‘a serious number of losers’, warns DeepMind co-founder
Reddit co-founder: The AI revolution is 'bigger than the smartphone'
Google expected to unveil its answer to Microsoft's AI search challenge
Microsoft ramps up A.I. game with bet on startup that helps coding novices build apps
AI lending firm Upstart jumps as $2 billion funding squeezes bears
Top AI papers
TidyBot: Personalized Robot Assistance with Large Language Models
abs: https://arxiv.org/abs/2305.05658
project page: https://tidybot.cs.princeton.edu
paper page: https://huggingface.co/papers/2305.05658
abstract: For a robot to personalize physical assistance effectively, it must learn user preferences that can be generally reapplied to future scenarios. In this work, we investigate personalization of household cleanup with robots that can tidy up rooms by picking up objects and putting them away. A key challenge is determining the proper place to put each object, as people's preferences can vary greatly depending on personal taste or cultural background. For instance, one person may prefer storing shirts in the drawer, while another may prefer them on the shelf. We aim to build systems that can learn such preferences from just a handful of examples via prior interactions with a particular person. We show that robots can combine language-based planning and perception with the few-shot summarization capabilities of large language models (LLMs) to infer generalized user preferences that are broadly applicable to future interactions. This approach enables fast adaptation and achieves 91.2% accuracy on unseen objects in our benchmark dataset. We also demonstrate our approach on a real-world mobile manipulator called TidyBot, which successfully puts away 85.0% of objects in real-world test scenarios.

FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
abs: https://arxiv.org/abs/2305.05176
paper page: https://huggingface.co/papers/2305.05176
abstract: There is a rapidly growing number of large language models (LLMs) that users can query for a fee. We review the cost associated with querying popular LLM APIs, e.g. GPT-4, ChatGPT, J1-Jumbo, and find that these models have heterogeneous pricing structures, with fees that can differ by two orders of magnitude. In particular, using LLMs on large collections of queries and text can be expensive. Motivated by this, we outline and discuss three types of strategies that users can exploit to reduce the inference cost associated with using LLMs: 1) prompt adaptation, 2) LLM approximation, and 3) LLM cascade. As an example, we propose FrugalGPT, a simple yet flexible instantiation of LLM cascade which learns which combinations of LLMs to use for different queries in order to reduce cost and improve accuracy. Our experiments show that FrugalGPT can match the performance of the best individual LLM (e.g. GPT-4) with up to 98% cost reduction or improve the accuracy over GPT-4 by 4% with the same cost. The ideas and findings presented here lay a foundation for using LLMs sustainably and efficiently.

InternChat: Solving Vision-Centric Tasks by Interacting with Chatbots Beyond Language
abs: https://arxiv.org/abs/2305.05662
paper page: https://huggingface.co/papers/2305.05662
github: https://github.com/OpenGVLab/InternChat
abstract: We present an interactive visual framework named InternChat, or iChat for short. The framework integrates chatbots that have planning and reasoning capabilities, such as ChatGPT, with non-verbal instructions like pointing movements that enable users to directly manipulate images or videos on the screen. Pointing (including gestures, cursors, etc.) movements can provide more flexibility and precision in performing vision-centric tasks that require fine-grained control, editing, and generation of visual content. The name InternChat stands for interaction, nonverbal, and chatbots. Different from existing interactive systems that rely on pure language, by incorporating pointing instructions, the proposed iChat significantly improves the efficiency of communication between users and chatbots, as well as the accuracy of chatbots in vision-centric tasks, especially in complicated visual scenarios where the number of objects is greater than 2. Additionally, in iChat, an auxiliary control mechanism is used to improve the control capability of LLM, and a large vision-language model termed Husky is fine-tuned for high-quality multi-modal dialogue (impressing ChatGPT-3.5-turbo with 93.89% GPT-4 Quality). We hope this work can spark new ideas and directions for future interactive visual systems.

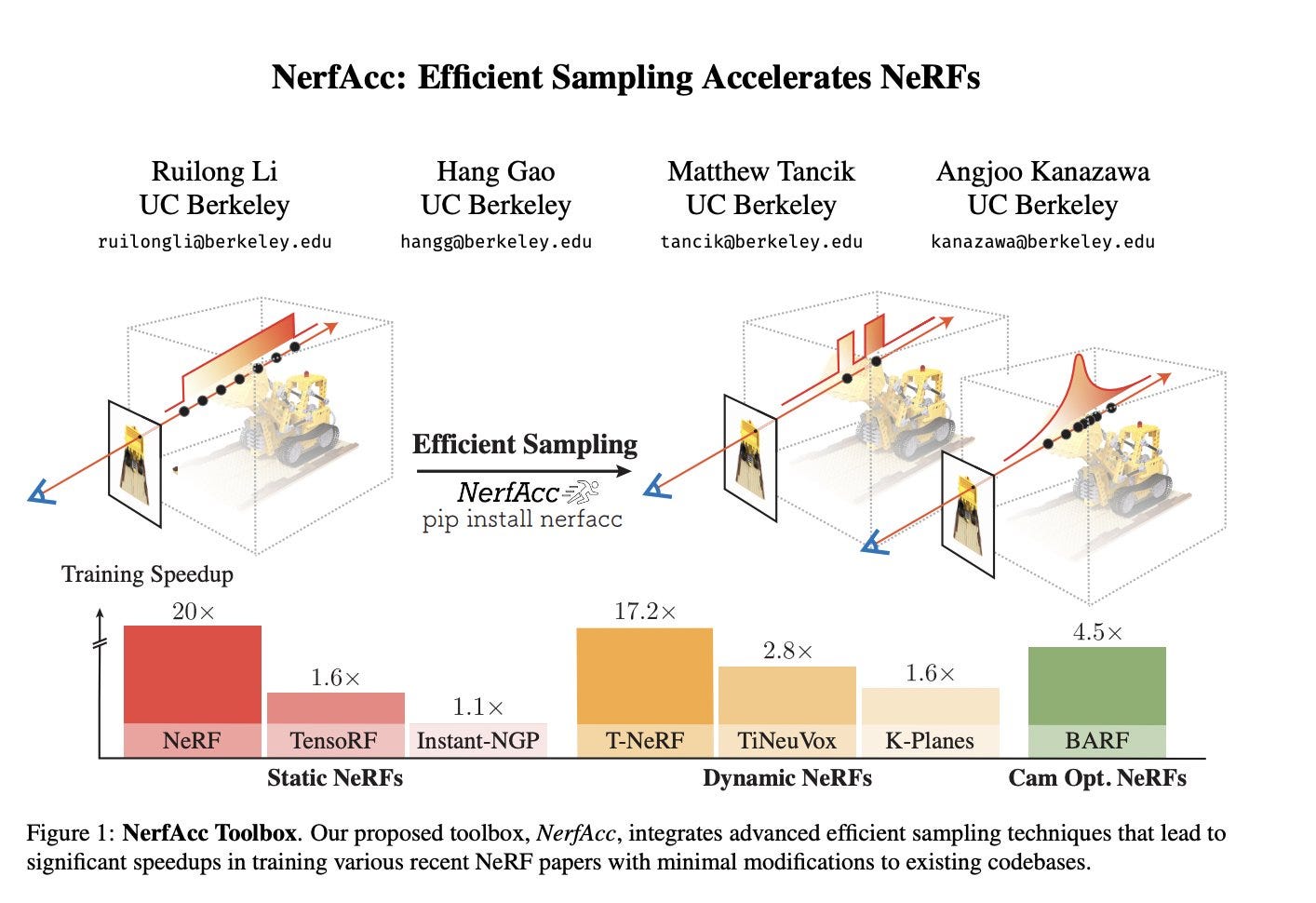
NerfAcc: Efficient Sampling Accelerates NeRFs
abs: https://arxiv.org/abs/2305.04966
project page: https://nerfacc.com/en/stable/
paper page: https://huggingface.co/papers/2305.04966
abstract: Optimizing and rendering Neural Radiance Fields is computationally expensive due to the vast number of samples required by volume rendering. Recent works have included alternative sampling approaches to help accelerate their methods, however, they are often not the focus of the work. In this paper, we investigate and compare multiple sampling approaches and demonstrate that improved sampling is generally applicable across NeRF variants under an unified concept of transmittance estimator. To facilitate future experiments, we develop NerfAcc, a Python toolbox that provides flexible APIs for incorporating advanced sampling methods into NeRF related methods. We demonstrate its flexibility by showing that it can reduce the training time of several recent NeRF methods by 1.5x to 20x with minimal modifications to the existing codebase. Additionally, highly customized NeRFs, such as Instant-NGP, can be implemented in native PyTorch using NerfAcc.
Recommender Systems with Generative Retrieval
abs: https://arxiv.org/abs/2305.05065
paper page: https://huggingface.co/papers/2305.05065
abstract: Modern recommender systems leverage large-scale retrieval models consisting of two stages: training a dual-encoder model to embed queries and candidates in the same space, followed by an Approximate Nearest Neighbor (ANN) search to select top candidates given a query's embedding. In this paper, we propose a new single-stage paradigm: a generative retrieval model which autoregressively decodes the identifiers for the target candidates in one phase. To do this, instead of assigning randomly generated atomic IDs to each item, we generate Semantic IDs: a semantically meaningful tuple of codewords for each item that serves as its unique identifier. We use a hierarchical method called RQ-VAE to generate these codewords. Once we have the Semantic IDs for all the items, a Transformer based sequence-to-sequence model is trained to predict the Semantic ID of the next item. Since this model predicts the tuple of codewords identifying the next item directly in an autoregressive manner, it can be considered a generative retrieval model. We show that our recommender system trained in this new paradigm improves the results achieved by current SOTA models on the Amazon dataset. Moreover, we demonstrate that the sequence-to-sequence model coupled with hierarchical Semantic IDs offers better generalization and hence improves retrieval of cold-start items for recommendations.
