


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
The Beatles will release a final record, using John Lennon's voice via an AI assist
France’s Mistral AI blows in with a $113M seed round at a $260M valuation to take on OpenAI
Top AI papers
Augmenting Language Models with Long-Term Memory
paper page: https://huggingface.co/papers/2306.07174
abstract: Existing large language models (LLMs) can only afford fix-sized inputs due to the input length limit, preventing them from utilizing rich long-context information from past inputs. To address this, we propose a framework, Language Models Augmented with Long-Term Memory (LongMem), which enables LLMs to memorize long history. We design a novel decoupled network architecture with the original backbone LLM frozen as a memory encoder and an adaptive residual side-network as a memory retriever and reader. Such a decoupled memory design can easily cache and update long-term past contexts for memory retrieval without suffering from memory staleness. Enhanced with memory-augmented adaptation training, LongMem can thus memorize long past context and use long-term memory for language modeling. The proposed memory retrieval module can handle unlimited-length context in its memory bank to benefit various downstream tasks. Typically, LongMem can enlarge the long-form memory to 65k tokens and thus cache many-shot extra demonstration examples as long-form memory for in-context learning. Experiments show that our method outperforms strong long-context models on ChapterBreak, a challenging long-context modeling benchmark, and achieves remarkable improvements on memory-augmented in-context learning over LLMs. The results demonstrate that the proposed method is effective in helping language models to memorize and utilize long-form contents

Retrieval-Enhanced Contrastive Vision-Text Models
paper page: https://huggingface.co/papers/2306.07196
abstract: Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.

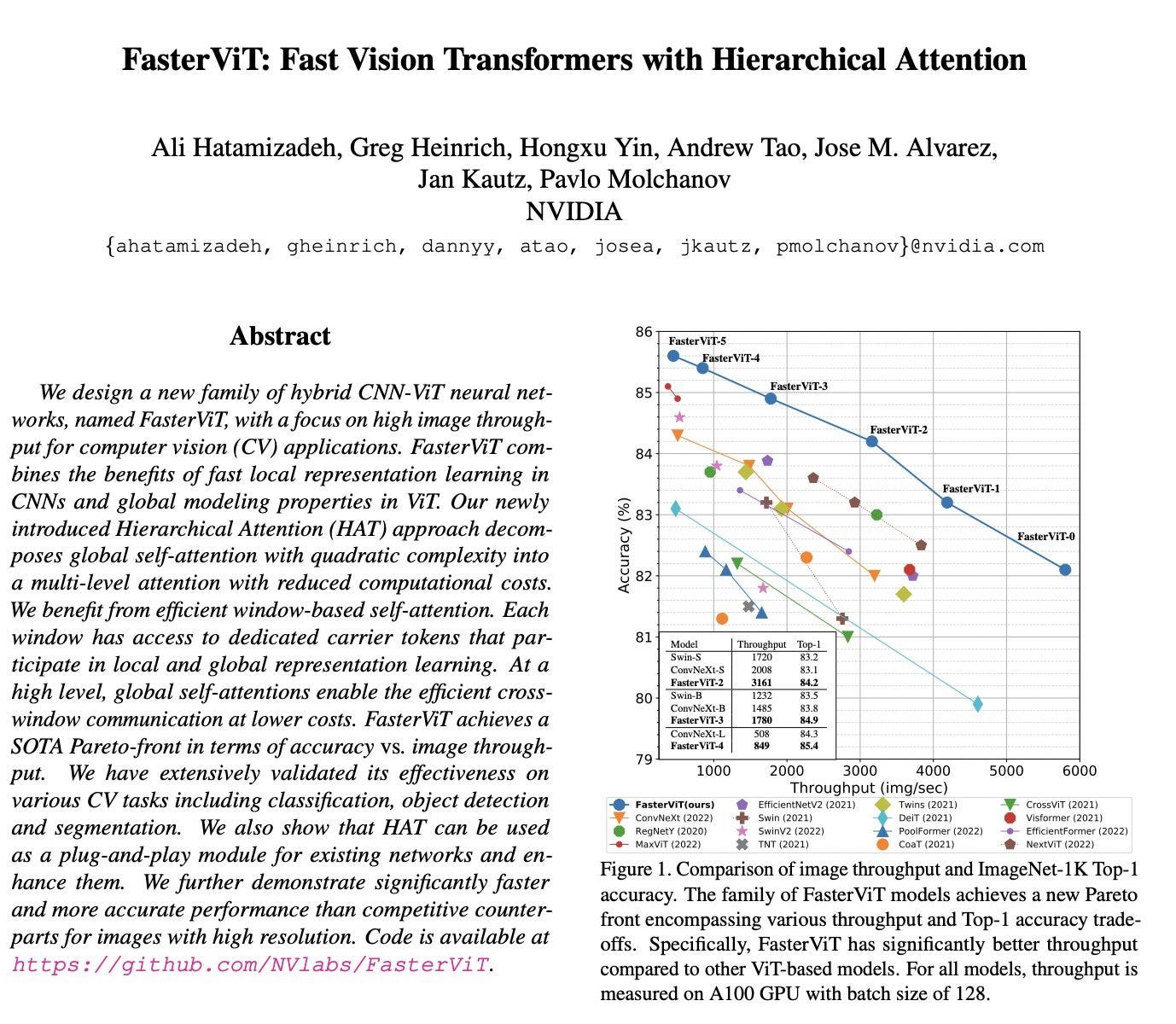
FasterViT: Fast Vision Transformers with Hierarchical Attention
paper page: https://huggingface.co/papers/2306.06189
abstract: We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy \vs image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution.
High-Fidelity Audio Compression with Improved RVQGAN
paper page: https://huggingface.co/papers/2306.06546
abstract: Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.

Face0: Instantaneously Conditioning a Text-to-Image Model on a Face
paper page: https://huggingface.co/papers/2306.06638
abstract: present Face0, a novel way to instantaneously condition a text-to-image generation model on a face, in sample time, without any optimization procedures such as fine-tuning or inversions. We augment a dataset of annotated images with embeddings of the included faces and train an image generation model, on the augmented dataset. Once trained, our system is practically identical at inference time to the underlying base model, and is therefore able to generate images, given a user-supplied face image and a prompt, in just a couple of seconds. Our method achieves pleasing results, is remarkably simple, extremely fast, and equips the underlying model with new capabilities, like controlling the generated images both via text or via direct manipulation of the input face embeddings. In addition, when using a fixed random vector instead of a face embedding from a user supplied image, our method essentially solves the problem of consistent character generation across images. Finally, while requiring further research, we hope that our method, which decouples the model's textual biases from its biases on faces, might be a step towards some mitigation of biases in future text-to-image models.
