


Trending AI news stories + papers
Today's Top AI news stories and papers

AI news stories
AI papers
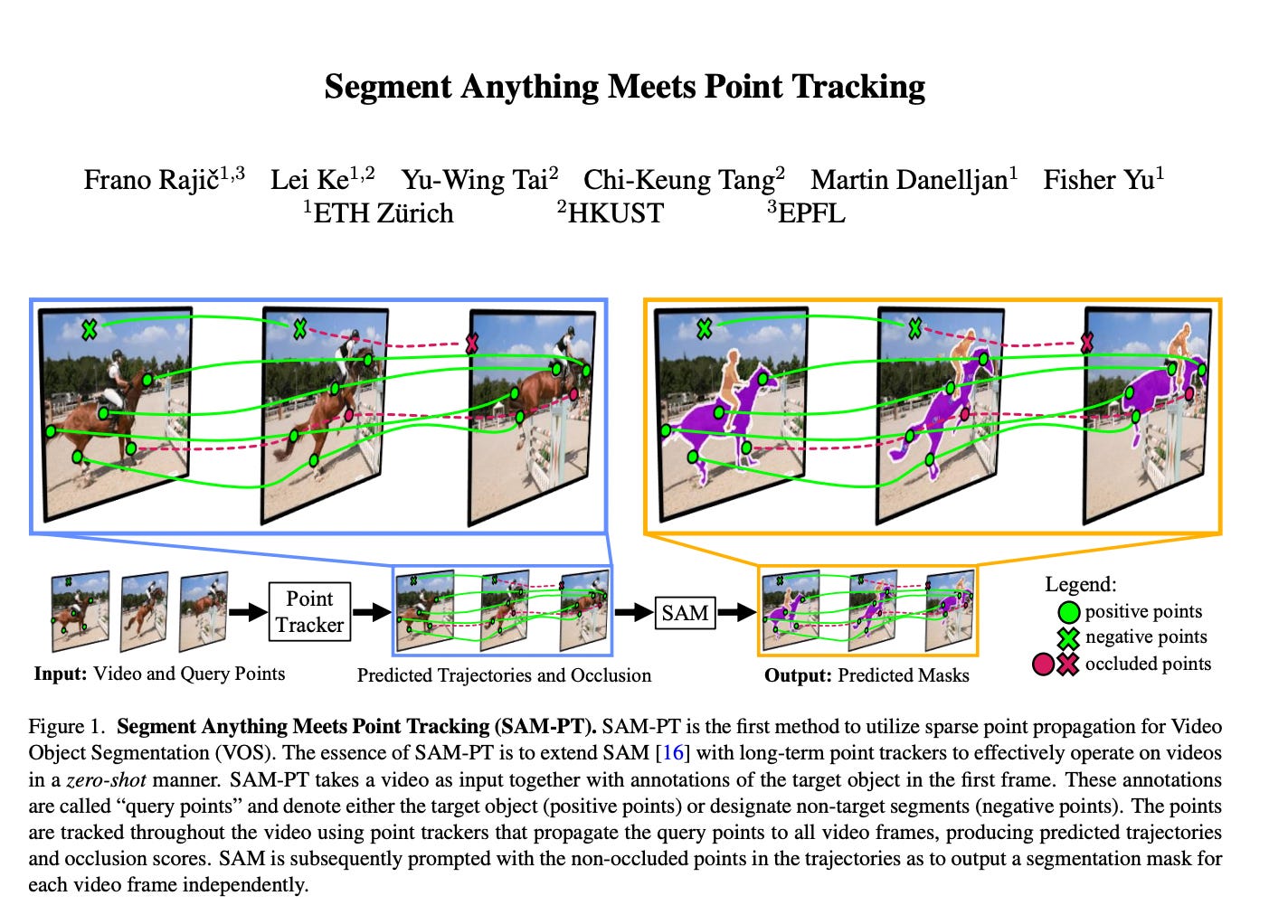
Segment Anything Meets Point Tracking
paper page: https://huggingface.co/papers/2307.01197
The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, employing interactive prompts such as points to generate masks. This paper presents SAM-PT, a method extending SAM's capability to tracking and segmenting anything in dynamic videos. SAM-PT leverages robust and sparse point selection and propagation techniques for mask generation, demonstrating that a SAM-based segmentation tracker can yield strong zero-shot performance across popular video object segmentation benchmarks, including DAVIS, YouTube-VOS, and MOSE. Compared to traditional object-centric mask propagation strategies, we uniquely use point propagation to exploit local structure information that is agnostic to object semantics. We highlight the merits of point-based tracking through direct evaluation on the zero-shot open-world Unidentified Video Objects (UVO) benchmark. To further enhance our approach, we utilize K-Medoids clustering for point initialization and track both positive and negative points to clearly distinguish the target object. We also employ multiple mask decoding passes for mask refinement and devise a point re-initialization strategy to improve tracking accuracy.

LEDITS: Real Image Editing with DDPM Inversion and Semantic Guidance
paper page: https://huggingface.co/papers/2307.00522
Recent large-scale text-guided diffusion models provide powerful image-generation capabilities. Currently, a significant effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. However, editing proves to be difficult for these generative models due to the inherent nature of editing techniques, which involves preserving certain content from the original image. Conversely, in text-based models, even minor modifications to the text prompt frequently result in an entirely distinct result, making attaining one-shot generation that accurately corresponds to the users intent exceedingly challenging. In addition, to edit a real image using these state-of-the-art tools, one must first invert the image into the pre-trained models domain - adding another factor affecting the edit quality, as well as latency. In this exploratory report, we propose LEDITS - a combined lightweight approach for real-image editing, incorporating the Edit Friendly DDPM inversion technique with Semantic Guidance, thus extending Semantic Guidance to real image editing, while harnessing the editing capabilities of DDPM inversion as well. This approach achieves versatile edits, both subtle and extensive as well as alterations in composition and style, while requiring no optimization nor extensions to the architecture.

Personality Traits in Large Language Models
paper page: https://huggingface.co/papers/2307.00184
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.

JourneyDB: A Benchmark for Generative Image Understanding
paper page: https://huggingface.co/papers/2307.00716
While recent advancements in vision-language models have revolutionized multi-modal understanding, it remains unclear whether they possess the capabilities of comprehending the generated images. Compared to real data, synthetic images exhibit a higher degree of diversity in both content and style, for which there are significant difficulties for the models to fully apprehend. To this end, we present a large-scale dataset, JourneyDB, for multi-modal visual understanding in generative images. Our curated dataset covers 4 million diverse and high-quality generated images paired with the text prompts used to produce them. We further design 4 benchmarks to quantify the performance of generated image understanding in terms of both content and style interpretation. These benchmarks include prompt inversion, style retrieval, image captioning and visual question answering. Lastly, we assess the performance of current state-of-the-art multi-modal models when applied to JourneyDB, and provide an in-depth analysis of their strengths and limitations in generated content understanding. We hope the proposed dataset and benchmarks will facilitate the research in the field of generative content understanding.



DisCo: Disentangled Control for Referring Human Dance Generation in Real World
paper page: https://huggingface.co/papers/2307.00040
Generative AI has made significant strides in computer vision, particularly in image/video synthesis conditioned on text descriptions. Despite the advancements, it remains challenging especially in the generation of human-centric content such as dance synthesis. Existing dance synthesis methods struggle with the gap between synthesized content and real-world dance scenarios. In this paper, we define a new problem setting: Referring Human Dance Generation, which focuses on real-world dance scenarios with three important properties: (i) Faithfulness: the synthesis should retain the appearance of both human subject foreground and background from the reference image, and precisely follow the target pose; (ii) Generalizability: the model should generalize to unseen human subjects, backgrounds, and poses; (iii) Compositionality: it should allow for composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce a novel approach, DISCO, which includes a novel model architecture with disentangled control to improve the faithfulness and compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DISCO can generate high-quality human dance images and videos with diverse appearances and flexible motions.

