Trending AI news stories + papers
Today's Top AI news stories and papers

AI news stories
Emmett Shear Becomes Interim OpenAI CEO as Altman Talks Break Down
Kyutai is a French AI research lab with a $330 million budget that will make everything open source
Exclusive: Germany, France and Italy reach agreement on future AI regulation
AI Repos
AI papers
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
paper page: https://huggingface.co/papers/2311.10093
Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one


UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
paper page: https://huggingface.co/papers/2311.09257
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.

Contrastive Chain-of-Thought Prompting
paper page: https://huggingface.co/papers/2311.09277
Despite the success of chain of thought in enhancing language model reasoning, the underlying process remains less well understood. Although logically sound reasoning appears inherently crucial for chain of thought, prior studies surprisingly reveal minimal impact when using invalid demonstrations instead. Furthermore, the conventional chain of thought does not inform language models on what mistakes to avoid, which potentially leads to more errors. Hence, inspired by how humans can learn from both positive and negative examples, we propose contrastive chain of thought to enhance language model reasoning. Compared to the conventional chain of thought, our approach provides both valid and invalid reasoning demonstrations, to guide the model to reason step-by-step while reducing reasoning mistakes. To improve generalization, we introduce an automatic method to construct contrastive demonstrations. Our experiments on reasoning benchmarks demonstrate that contrastive chain of thought can serve as a general enhancement of chain-of-thought prompting

Adaptive Shells for Efficient Neural Radiance Field Rendering
paper page: https://huggingface.co/papers/2311.10091
Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces which can be accurately rendered by a single sample per pixel. Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope which spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample. To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with width determined by the kernel size, and fine-tune the radiance field within this band. At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation

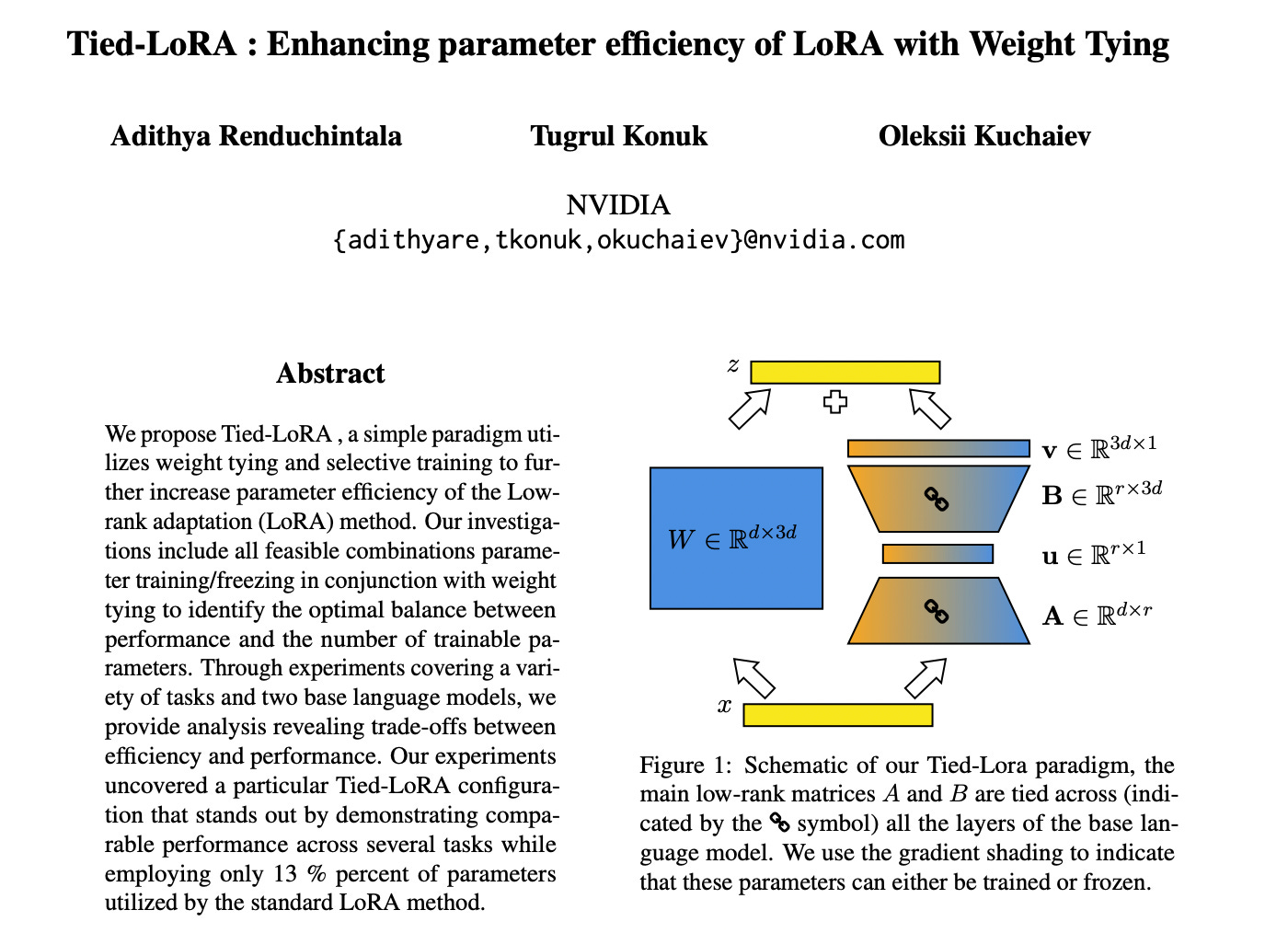
Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying
paper page: https://huggingface.co/papers/2311.09578
We propose Tied-LoRA, a simple paradigm utilizes weight tying and selective training to further increase parameter efficiency of the Low-rank adaptation (LoRA) method. Our investigations include all feasible combinations parameter training/freezing in conjunction with weight tying to identify the optimal balance between performance and the number of trainable parameters. Through experiments covering a variety of tasks and two base language models, we provide analysis revealing trade-offs between efficiency and performance. Our experiments uncovered a particular Tied-LoRA configuration that stands out by demonstrating comparable performance across several tasks while employing only 13~\% percent of parameters utilized by the standard LoRA method.