


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
OpenAI chief set to call for greater regulation of artificial intelligence
Tom Hanks: I could appear in movies after death with AI technology
Google Cloud launches A.I.-powered tools to accelerate drug discovery, precision medicine
Alphabet Adds $115 Billion in Value After Defying AI Doubters
Top AI papers
Dr. LLaMA: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
paper page: https://huggingface.co/papers/2305.07804
abstract: Large Language Models (LLMs) have made significant strides in natural language processing but face challenges in terms of computational expense and inefficiency as they grow in size, especially in domain-specific tasks. Small Language Models (SLMs), on the other hand, often struggle in these tasks due to limited capacity and training data. In this paper, we introduce Dr. LLaMA, a method for improving SLMs through generative data augmentation using LLMs, focusing on medical question-answering tasks and the PubMedQA dataset. Our findings indicate that LLMs effectively refine and diversify existing question-answer pairs, resulting in improved performance of a much smaller model on domain-specific QA datasets after fine-tuning. This study highlights the challenges of using LLMs for domain-specific question answering and suggests potential research directions to address these limitations, ultimately aiming to create more efficient and capable models for specialized applications. We have also made our code available for interested researchers


TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
paper page: https://huggingface.co/papers/2305.07759
abstract: Language models (LMs) are powerful tools for natural language processing, but they often struggle to produce coherent and fluent text when they are small. Models with around 125M parameters such as GPT-Neo (small) or GPT-2 (small) can rarely generate coherent and consistent English text beyond a few words even after extensive training. This raises the question of whether the emergence of the ability to produce coherent English text only occurs at larger scales (with hundreds of millions of parameters or more) and complex architectures (with many layers of global attention).
In this work, we introduce TinyStories, a synthetic dataset of short stories that only contain words that a typical 3 to 4-year-olds usually understand, generated by GPT-3.5 and GPT-4. We show that TinyStories can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters), or have much simpler architectures (with only one transformer block), yet still produce fluent and consistent stories with several paragraphs that are diverse and have almost perfect grammar, and demonstrate reasoning capabilities. We also introduce a new paradigm for the evaluation of language models: We suggest a framework which uses GPT-4 to grade the content generated by these models as if those were stories written by students and graded by a (human) teacher. This new paradigm overcomes the flaws of standard benchmarks which often requires the model's output to be very structures, and moreover provides a multidimensional score for the model, providing scores for different capabilities such as grammar, creativity and consistency. We hope that TinyStories can facilitate the development, analysis and research of LMs, especially for low-resource or specialized domains, and shed light on the emergence of language capabilities in LMs.

DarkBERT: A Language Model for the Dark Side of the Internet
paper page: https://huggingface.co/papers/2305.08596
abstract: Recent research has suggested that there are clear differences in the language used in the Dark Web compared to that of the Surface Web. As studies on the Dark Web commonly require textual analysis of the domain, language models specific to the Dark Web may provide valuable insights to researchers. In this work, we introduce DarkBERT, a language model pretrained on Dark Web data. We describe the steps taken to filter and compile the text data used to train DarkBERT to combat the extreme lexical and structural diversity of the Dark Web that may be detrimental to building a proper representation of the domain. We evaluate DarkBERT and its vanilla counterpart along with other widely used language models to validate the benefits that a Dark Web domain specific model offers in various use cases. Our evaluations show that DarkBERT outperforms current language models and may serve as a valuable resource for future research on the Dark Web.

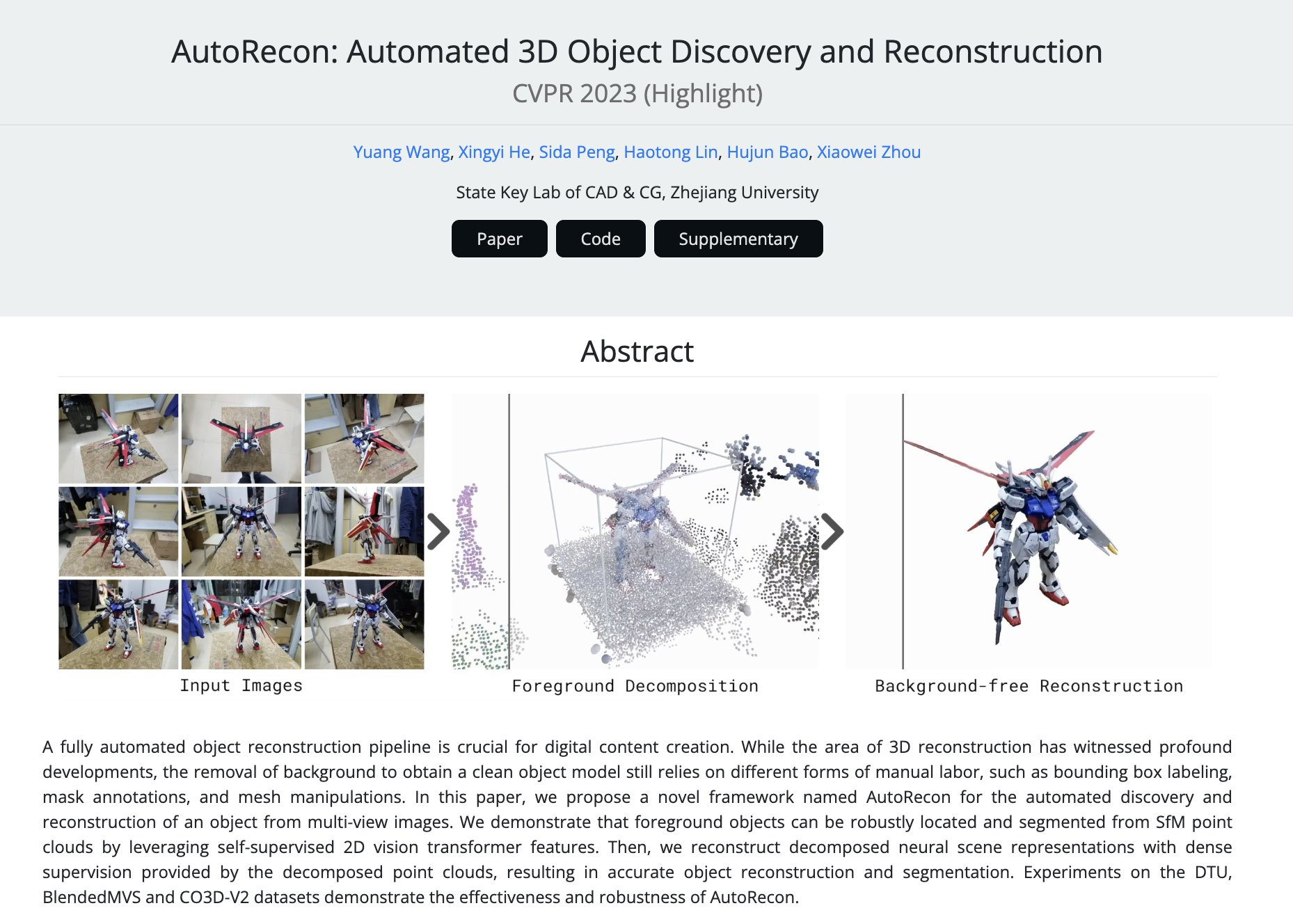
AutoRecon: Automated 3D Object Discovery and Reconstruction
paper page: https://huggingface.co/papers/2305.08810
project page: https://zju3dv.github.io/autorecon/
abstract: A fully automated object reconstruction pipeline is crucial for digital content creation. While the area of 3D reconstruction has witnessed profound developments, the removal of background to obtain a clean object model still relies on different forms of manual labor, such as bounding box labeling, mask annotations, and mesh manipulations. In this paper, we propose a novel framework named AutoRecon for the automated discovery and reconstruction of an object from multi-view images. We demonstrate that foreground objects can be robustly located and segmented from SfM point clouds by leveraging self-supervised 2D vision transformer features. Then, we reconstruct decomposed neural scene representations with dense supervision provided by the decomposed point clouds, resulting in accurate object reconstruction and segmentation. Experiments on the DTU, BlendedMVS and CO3D-V2 datasets demonstrate the effectiveness and robustness of AutoRecon.
Improved baselines for vision-language pre-training
paper page: https://huggingface.co/papers/2305.08675
abstract: Contrastive learning has emerged as an efficient framework to learn multimodal representations. CLIP, a seminal work in this area, achieved impressive results by training on paired image-text data using the contrastive loss. Recent work claims improvements over CLIP using additional non-contrastive losses inspired from self-supervised learning. However, it is sometimes hard to disentangle the contribution of these additional losses from other implementation details, e.g., data augmentation or regularization techniques, used to train the model. To shed light on this matter, in this paper, we first propose, implement and evaluate several baselines obtained by combining contrastive learning with recent advances in self-supervised learning. In particular, we use the loss functions that were proven successful for visual self-supervised learning to align image and text modalities. We find that these baselines outperform a basic implementation of CLIP. However, when a stronger training recipe is employed, the advantage disappears. Indeed, we find that a simple CLIP baseline can also be improved substantially, up to a 25% relative improvement on downstream zero-shot tasks, by using well-known training techniques that are popular in other subfields. Moreover, we discover that it is enough to apply image and text augmentations to make up for most of the improvement attained by prior works. With our improved training recipe for CLIP, we obtain state-of-the-art performance on four standard datasets, and consistently outperform prior work (up to +4% on the largest dataset), while being substantially simpler.
