


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
Apple reportedly limits internal use of AI-powered tools like ChatGPT and GitHub Copilot
After OpenAI hearing, A.I. experts urge Congress to listen to more diverse voices on regulation
Top AI papers
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
paper page: https://huggingface.co/papers/2305.10973
abstract: Synthesizing visual content that meets users' needs often requires flexible and precise controllability of the pose, shape, expression, and layout of the generated objects. Existing approaches gain controllability of generative adversarial networks (GANs) via manually annotated training data or a prior 3D model, which often lack flexibility, precision, and generality. In this work, we study a powerful yet much less explored way of controlling GANs, that is, to "drag" any points of the image to precisely reach target points in a user-interactive manner, as shown in Fig.1. To achieve this, we propose DragGAN, which consists of two main components: 1) a feature-based motion supervision that drives the handle point to move towards the target position, and 2) a new point tracking approach that leverages the discriminative generator features to keep localizing the position of the handle points. Through DragGAN, anyone can deform an image with precise control over where pixels go, thus manipulating the pose, shape, expression, and layout of diverse categories such as animals, cars, humans, landscapes, etc. As these manipulations are performed on the learned generative image manifold of a GAN, they tend to produce realistic outputs even for challenging scenarios such as hallucinating occluded content and deforming shapes that consistently follow the object's rigidity. Both qualitative and quantitative comparisons demonstrate the advantage of DragGAN over prior approaches in the tasks of image manipulation and point tracking. We also showcase the manipulation of real images through GAN inversion.

GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework
paper page: https://huggingface.co/papers/2305.10841
project page: https://ai-muzic.github.io/getmusic/
abstract: Symbolic music generation aims to create musical notes, which can help users compose music, such as generating target instrumental tracks from scratch, or based on user-provided source tracks. Considering the diverse and flexible combination between source and target tracks, a unified model capable of generating any arbitrary tracks is of crucial necessity. Previous works fail to address this need due to inherent constraints in music representations and model architectures. To address this need, we propose a unified representation and diffusion framework named GETMusic (`GET' stands for GEnerate music Tracks), which includes a novel music representation named GETScore, and a diffusion model named GETDiff. GETScore represents notes as tokens and organizes them in a 2D structure, with tracks stacked vertically and progressing horizontally over time. During training, tracks are randomly selected as either the target or source. In the forward process, target tracks are corrupted by masking their tokens, while source tracks remain as ground truth. In the denoising process, GETDiff learns to predict the masked target tokens, conditioning on the source tracks. With separate tracks in GETScore and the non-autoregressive behavior of the model, GETMusic can explicitly control the generation of any target tracks from scratch or conditioning on source tracks. We conduct experiments on music generation involving six instrumental tracks, resulting in a total of 665 combinations. GETMusic provides high-quality results across diverse combinations and surpasses prior works proposed for some specific combinations.

LDM3D: Latent Diffusion Model for 3D
paper page: https://huggingface.co/papers/2305.10853
abstract: This research paper proposes a Latent Diffusion Model for 3D (LDM3D) that generates both image and depth map data from a given text prompt, allowing users to generate RGBD images from text prompts. The LDM3D model is fine-tuned on a dataset of tuples containing an RGB image, depth map and caption, and validated through extensive experiments. We also develop an application called DepthFusion, which uses the generated RGB images and depth maps to create immersive and interactive 360-degree-view experiences using TouchDesigner. This technology has the potential to transform a wide range of industries, from entertainment and gaming to architecture and design. Overall, this paper presents a significant contribution to the field of generative AI and computer vision, and showcases the potential of LDM3D and DepthFusion to revolutionize content creation and digital experiences.

Discriminative Diffusion Models as Few-shot Vision and Language Learners
paper page: https://huggingface.co/papers/2305.10722
abstract: Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.

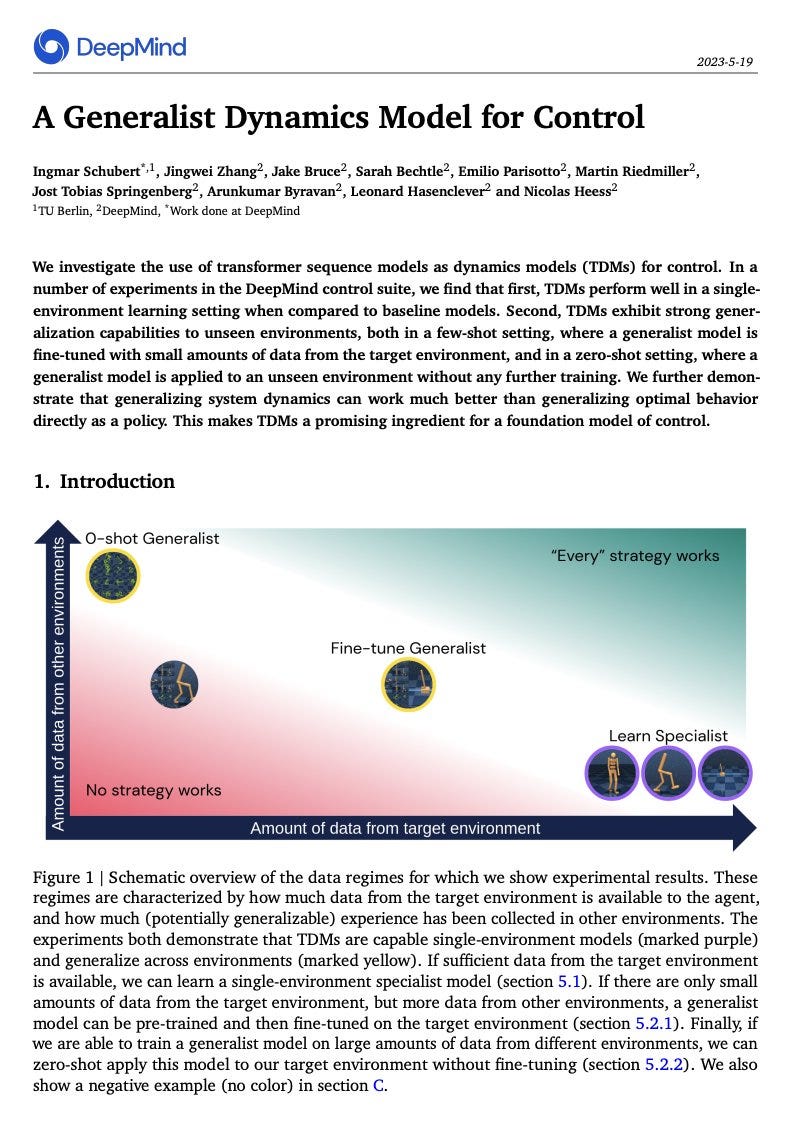
A Generalist Dynamics Model for Control
paper page: https://huggingface.co/papers/2305.10912
abstract: We investigate the use of transformer sequence models as dynamics models (TDMs) for control. In a number of experiments in the DeepMind control suite, we find that first, TDMs perform well in a single-environment learning setting when compared to baseline models. Second, TDMs exhibit strong generalization capabilities to unseen environments, both in a few-shot setting, where a generalist model is fine-tuned with small amounts of data from the target environment, and in a zero-shot setting, where a generalist model is applied to an unseen environment without any further training. We further demonstrate that generalizing system dynamics can work much better than generalizing optimal behavior directly as a policy. This makes TDMs a promising ingredient for a foundation model of control.
They will no longer upload content?