


Trending AI news stories + papers
Today's Top AI news stories and papers

Top AI news stories
Top AI papers
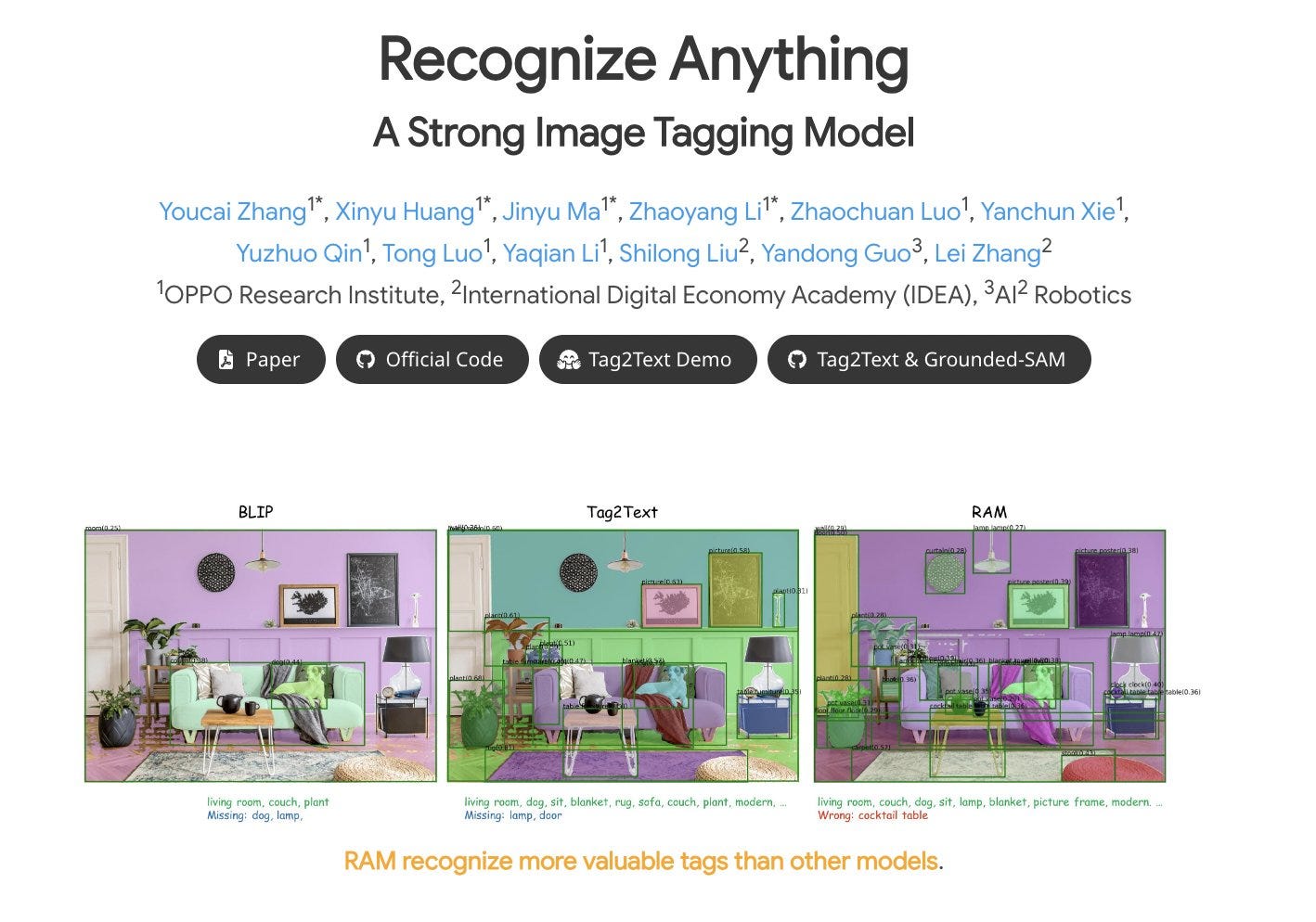
Recognize Anything: A Strong Image Tagging Model
paper page: https://huggingface.co/papers/2306.03514
abstract: We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM can recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google API.
Emergent Correspondence from Image Diffusion
paper page: https://huggingface.co/papers/2306.03881
abstract: Finding correspondences between images is a fundamental problem in computer vision. In this paper, we show that correspondence emerges in image diffusion models without any explicit supervision. We propose a simple strategy to extract this implicit knowledge out of diffusion networks as image features, namely DIffusion FeaTures (DIFT), and use them to establish correspondences between real images. Without any additional fine-tuning or supervision on the task-specific data or annotations, DIFT is able to outperform both weakly-supervised methods and competitive off-the-shelf features in identifying semantic, geometric, and temporal correspondences. Particularly for semantic correspondence, DIFT from Stable Diffusion is able to outperform DINO and OpenCLIP by 19 and 14 accuracy points respectively on the challenging SPair-71k benchmark. It even outperforms the state-of-the-art supervised methods on 9 out of 18 categories while remaining on par for the overall performance.

Deductive Verification of Chain-of-Thought Reasoning
paper page: https://huggingface.co/papers/2306.03872
abstract: Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inadvertently introduce hallucinations and accumulated errors, thereby limiting models' ability to solve complex reasoning tasks. Inspired by how humans engage in careful and meticulous deductive logical reasoning processes to solve tasks, we seek to enable language models to perform explicit and rigorous deductive reasoning, and also ensure the trustworthiness of their reasoning process through self-verification. However, directly verifying the validity of an entire deductive reasoning process is challenging, even with advanced models like ChatGPT. In light of this, we propose to decompose a reasoning verification process into a series of step-by-step subprocesses, each only receiving their necessary context and premises. To facilitate this procedure, we propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. By integrating this verification process into each deductive reasoning stage, we significantly enhance the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks.

Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
paper page: https://huggingface.co/papers/2306.03509
abstract: Scaling text-to-speech to a large and wild dataset has been proven to be highly effective in achieving timbre and speech style generalization, particularly in zero-shot TTS. However, previous works usually encode speech into latent using audio codec and use autoregressive language models or diffusion models to generate it, which ignores the intrinsic nature of speech and may lead to inferior or uncontrollable results. We argue that speech can be decomposed into several attributes (e.g., content, timbre, prosody, and phase) and each of them should be modeled using a module with appropriate inductive biases. From this perspective, we carefully design a novel and large zero-shot TTS system called Mega-TTS, which is trained with large-scale wild data and models different attributes in different ways: 1) Instead of using latent encoded by audio codec as the intermediate feature, we still choose spectrogram as it separates the phase and other attributes very well. Phase can be appropriately constructed by the GAN-based vocoder and does not need to be modeled by the language model. 2) We model the timbre using global vectors since timbre is a global attribute that changes slowly over time. 3) We further use a VQGAN-based acoustic model to generate the spectrogram and a latent code language model to fit the distribution of prosody, since prosody changes quickly over time in a sentence, and language models can capture both local and long-range dependencies. We scale Mega-TTS to multi-domain datasets with 20K hours of speech and evaluate its performance on unseen speakers. Experimental results demonstrate that Mega-TTS surpasses state-of-the-art TTS systems on zero-shot TTS, speech editing, and cross-lingual TTS tasks, with superior naturalness, robustness, and speaker similarity due to the proper inductive bias of each module.

Natural Language Commanding via Program Synthesis
paper page: https://huggingface.co/papers/2306.03460
abstract: We present Semantic Interpreter, a natural language-friendly AI system for productivity software such as Microsoft Office that leverages large language models (LLMs) to execute user intent across application features. While LLMs are excellent at understanding user intent expressed as natural language, they are not sufficient for fulfilling application-specific user intent that requires more than text-to-text transformations. We therefore introduce the Office Domain Specific Language (ODSL), a concise, high-level language specialized for performing actions in and interacting with entities in Office applications. Semantic Interpreter leverages an Analysis-Retrieval prompt construction method with LLMs for program synthesis, translating natural language user utterances to ODSL programs that can be transpiled to application APIs and then executed. We focus our discussion primarily on a research exploration for Microsoft PowerPoint.
